大二数据结构
一.绪论
看看就行,需要你会时间空间复杂度分析
二.线性表
1.顺序表
数组。
- 第$i$个元素的地址,$loc(a_i) = loc(a_0)+i*k$ ,其中$k$是单个元素的内存大小
- 插入、删除元素复杂度$O(n)$
2.线性表
链表。 这部分代码要注意空指针的情况
单链表
typedef strcut node{
Elemtype element; //数据域
struct node*next //指针域
}Node;
要求会写:
- 单链表结点增加(指针$p$先遍历到要插入的位置前,插入结点指向未插入前的结点的下一个结点,再使未插入前的结点指向插入结点)
- 单链表结点删除(指针$p$先遍历到要删除的位置前,当前结点指向要删除的结点的下一个节点,再释放掉要删除结点的空间)
- 在单链表的基础上加入一个表头结点。表头结点的数据域没有元素,链表为空时表头结点也存在
- 插入删除时间复杂度$O(1)$,读取$O(n)$
- 空间复杂度在需求空间未知时比较优秀
单循环链表
单链表的最后一个结点指向头结点
双向链表
在单链表的基础上再增加指向每个结点前面一个结点的指针
3.线性表的应用
多项式的运算
…
三.堆栈和队列
栈
为啥要叫堆栈而不是栈呢
用数组模拟栈
对于大小为$n$的栈
当栈为空top=-1
加入元素stk[++top]=ele
队列
采用循环队列结构防止数据溢出
利用取余进行运算
使用两个指针front和rear
空队列front ==rear
满队列front == (rear+1)%maxSize ,满队列情况下实际数组剩余一个空间
添加元素:rear=(rear+1)%maxSize;q[rear]=ele;
删除元素同理
后缀表达式
从左到右扫描表达式,如果遇到操作数,放入栈中,如果遇到操作符,取出栈顶两个操作数,先出栈的是右操作数
中缀表达式转后缀表达式
四.数组与字符串
存储顺序
- 行优先存储
- 列优先存储
稀疏矩阵
存储方法:三元组
转置方法1:
- 依次访问三元组,将行号和列号互换
- 按照行号和列号升序排序
转置方法2:
- 访问三元组$n$次,每次查询列下标为$j++$的三元组,将其放入新三元组中(因为行号是升序的,所以新三元组列号也是升序的)
- 时间复杂度$O(n \times t)$
转置方法3:
- 两个数组,$num$数组和$K$数组 :$num[i]$统计矩阵中列号为$i$的非零元素个数,$K[i]$统计矩阵中列从$0$到$i-1$的非零元素个数,即原矩阵中每一列从上往下第一个元素
- 遍历原来三元组中所有数据,先取出它的列数$j$ ,那么第$j$列的元素下标就应该是$K[j]$,由于新三元组是按列优先存储,那么第$K[j]$个元素就是当前元素,同时将$K[j]+1$
- 时间复杂度$O(n+t)$
字符串匹配
简单的$O(n+m)$很简单
$kmp$?
五.二叉树
1.定义和性质
- 结点的度:这里度代表结点儿子的个数,因此叶子节点的度数为$0$
- 若树的子树是有序的,那么称为有序树,反之则为无序树
- 单独一个根节点时树的高度为$1$
- 二叉树高度为$h$时,最多有$2^h -1$个结点
- 二叉树若度数为$2$的结点个数为$n$,则叶子结点个数为$n+1$
- 满二叉树和完全二叉树的定义
- 不存在度数为$1$的二叉树称为扩充二叉树
- 二叉树的顺序存储:结点$u$编号是$k$,则两个儿子结点编号分别为$2k+1$,$2k+2$
- 二叉树的链表表示
2.二叉树
先中后序遍历需要会写,层次遍历就是每一层从左往右遍历,用队列即可
树和森林的转换
这部分内容让我感到匪夷所思,不知道用来干啥的
树转换成二叉树:
- 所有兄弟结点连线
- 所有结点只保留最左边儿子的连线,与其他儿子的连线断开
- 将树顺时针旋转,变成一颗二叉树
森林转换成二叉树:
- 将每棵树转换成二叉树
- 后一颗二叉树的根节点作为前一颗二叉树的右儿子
二叉树转换成树:
- 若某节点是左孩子,那么将该节点的右孩子,右孩子的右孩子..与该节点的父节点连接
- 删除二叉树中所有节点和右孩子的连线
- 逆时针旋转,变成一棵树
二叉树转换成森林:
- 删除二叉树根节点右链上所有节点与其右孩子的连线,分成若干个二叉树
- 分别将这些二叉树还原成一棵树
存储
多重链表:
- 优点:结构简单
- 空指针域多,空间浪费
孩子兄弟表示法
->三重链表:每个节点lchild,rchild,father指针
顺序结构表示法
遍历
先中后序DFS和层次遍历..
堆和优先队列
最大堆:一颗完全二叉树,父节点比子节点大。 最小堆类似 显然堆顶(根节点)的值是整个堆中 最大/最小的
顺序表存储:结点$i$的两个儿子是$2i+1$,$2i+2$
int heap[M];
int n;
堆的插入,删除操作(最大堆作为示例) 下标从$1$开始
先将要插入的元素放入数组末尾,观察它与父节点的大小,若不满足堆的性质则需调整:它与父节点交换位置。
void up(int p){
while(p>1){
if(heap[p]>heap[p/2]){
swap(heap[p],heap[p/2]);
p=p/2;
}else break;
}
}
void insert(int val){
heap[++n]=val;
up(n);
}
取出堆顶元素
int Get(){
return heap[1];
}
删除堆顶元素时 将数组末尾元素放入堆顶,观察是否满足堆的性质进行向下调整
void down(int p){
int s=2*p;//下标从1开始的左节点
while(s<=n){
if(s<n&&heap[s]<heap[s+1])s=s+1;//取左右儿子中最大的那个进行比较
if(heap[s]>heap[p]){
swap(heap[s],heap[p]);
p=s,s=p*2;
}else break;
}
}
void pop(){
heap[1]=heap[n--];
down(1);
}
优先队列
堆的应用:取出元素时总是取出优先级最大的那个 单次操作时间复杂度$O(logn)$
霍夫曼编码
- 加权路径长度$WPL$:为每个叶子节点到根节点的距离长度乘以权值的和
- 霍夫曼树是具有最小$WPL$的二叉树
- 有$n$个叶节点的霍夫曼树结点总数为$2n-1$
- 树的内路径长度:除叶节点外,所有节点到根节点的路径长度之和
- 树的外路径长度:所有叶节点到根节点的路径长度之和
构建霍夫曼树:
- 把所有节点加入最小堆中
- 取出堆中两个权值最小的节点,生成一个新节点,权值是这两个节点权值之和,并把它与两个节点连接起来
- 把这个新节点塞入堆中
- 继续上述过程直到堆中只剩一个节点
- 最后构建的二叉树:往左的边编码为$0$,往右的边编码为$1$
- 显然这样构建的霍夫曼树:权值最大的节点编码长度最短
六.集合和搜索
集合
除了多重集,元素互不相同 分为几种
- 无序集{1,2,3}
- 有序集(1,2,3)
- 多重集{1,1,2,3}
可以插入,删除的称为动态集
搜索
其实是在集合中查找元素,不是dfs和bfs
平均搜索长度$ASL$:搜索过程中,给定值和集合中元素的关键字比较的平均次数。分为搜索成功和搜索失败两种
顺序搜索:从$0$到$n-1$遍历
无序表(没排序过的数组)中搜索 成功:$ASL=(n+1)/2$ 失败:$ASL=n$
有序表((按关键字)排过序的数组)中搜索 成功:$ASL=(n+1)/2$ 失败:$ASL=n/2+2$
二分查找(对半搜索) 显然是在有序表上进行
课本上的二分代码
int bs(listset L,int x){
int m,l=0,r=L.n-1;
while(l<=r){
m=(l+r)/2;
if(x<L.ele[m])r=m-1;
else if(x>L.ele[m])l=m+1;
else return m;
}
return -1;
}
搜索成功和失败的平均时间复杂度是$O(logn)$
二叉判定树
构建过程
- 选取当前区间的中间索引($n/2$向下取整)
- 将其作为当前子树的根节点,左右两边区间分别作为左右子树
- 继续上述操作直到区间只剩下一个下标,即当前节点为叶节点
- 构建外部节点:叶节点的左儿子是叶节点索引-1,右儿子是叶节点索引
成功情况:$ASL_s$ :除了外部节点,( 不同层次节点的层数 乘以 该层的节点个数 之和 )除以 有序表长度 失败情况:$ASL_f$: (层数 乘以 该层节点拥有的外部节点孩子的个数)除以 外部节点个数
七.搜索树
二叉搜索树(BST)
所有的左子树节点权值都小于根节点权值 所有的右子树节点权值都大于根节点权值
查找,插入,都是从根节点向下走
删除: 如果删除的是叶节点,直接删除 如果删除的是只有一个子树的节点,直接用子树替代该节点 否则用 左子树最大的节点/右子树最小的节点 替代该节点
平衡二叉树(AVL)
一颗二叉搜索树, (左子树高度和右子树高度差)(平衡因子)的绝对值小于等于1
一颗$AVL$的平衡因子一定是(-1,0,1)中的一种
插入节点后如果导致多个祖先节点失衡 只需要调整距离插入节点最近的失衡节点
删除节点后需要依次向上对每个祖先节点检查并调整失衡节点
调整策略:
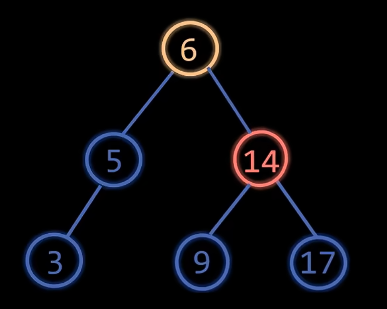
LL型
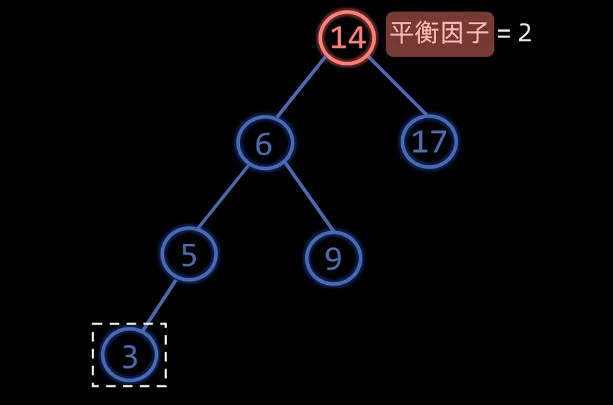
特征:失衡节点的平衡因子为$2$ ,失衡节点的左孩子的平衡因子为$1$
操作:右旋,左子树的右孩变为失衡节点,右孩变为失衡节点的左孩
LR型
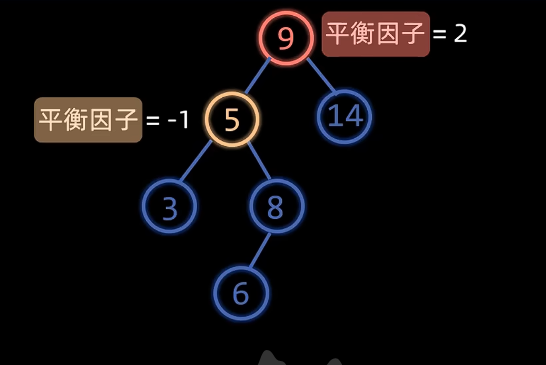
特征:失衡节点的平衡因子为$2$,左孩子的平衡因子为$-1$
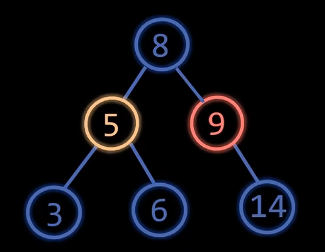
操作:如上图, 先左旋节点5,再右旋节点9
解释:节点5当节点8的左孩子,节点9当节点8的右孩子
因为节点5的平衡因子是$-1$,排除节点8,那么它的两个子树大小相同
因为节点9的平衡因子是$-2$,排除节点5和节点8,那么节点8的平衡因子是$0$
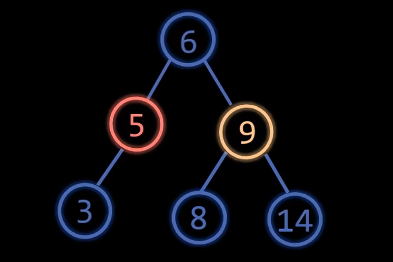
RL型
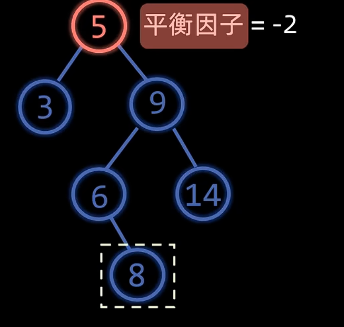 特征:失衡节点的平衡因子为$-2$,左孩子的平衡因子为$1$
特征:失衡节点的平衡因子为$-2$,左孩子的平衡因子为$1$
操作:如上图,
先右旋节点9,再左旋节点5
RR型
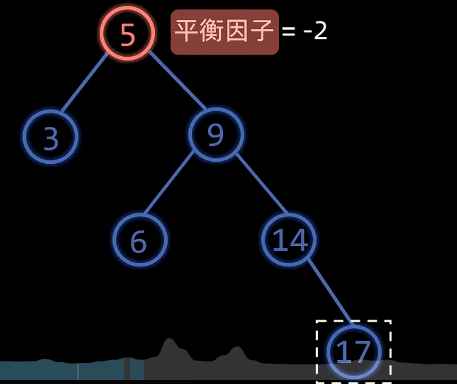 特征:失衡节点的平衡因子为$-2$ ,失衡节点的左孩子的平衡因子为$-1$
特征:失衡节点的平衡因子为$-2$ ,失衡节点的左孩子的平衡因子为$-1$
操作:左旋,右子树的左孩变为失衡节点,左孩变为失衡节点的右孩
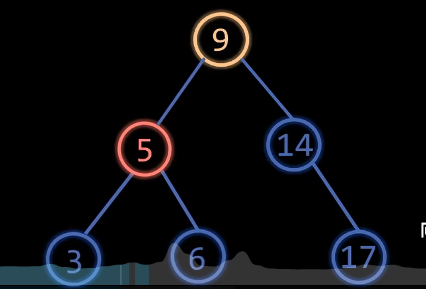
B树
B树(B-树) - 来由, 定义, 插入, 构建_哔哩哔哩_bilibili
访问节点是在硬盘中进行的,节点内的数据操作是在内存中进行的
一颗多叉平衡搜索树
特征:
- 所有叶节点都在同一层
- 节点内权值有序,且满足搜索树的条件
- 对于$m$阶的$B$树,每个节点最多$m$个分支,$m-1$个元素。最少:根节点$2$个分支,$1$个元素。其他节点:$\lceil m/2 \rceil$个分支,$\lceil m/2 \rceil -1$个元素
查找和二叉搜索树类似
插入: 先找到要插入的位置,如果没有溢出(节点元素超过上限),无需调整 否则中间元素$\lceil m/2 \rceil$上移,两边分裂(直到没有溢出为止)
删除:
B+树
广泛作为数据库的索引结构
八.散列表
哈希表是一种存储结构,主要是通过映射的关系存储元素集合
散列函数
需要满足
- 同一值总是映射到同一地址
- 计算简单
- 尽量覆盖整个存储空间
- 避免哈希碰撞 ,若两个值的哈希值相同,那么称这两个值为同义词
常见的函数:
- 除留余数法 h(key)=h(key)%P, (M是散列表长度,P是比M小一点的素数) 相邻的关键字会映射到相邻地址
改进: h(key)=(key x a +b) %p (a>0,b>0 ,a%p !=0)
平方取中法 h(key) =$(key)^2$ 的中间若干位$k$ 位数$k$满足:$10^{k-1} \lt n \leq 10^k$
折叠法 把$key$从左往右分为位数相等的几部分,将数据叠加起来得到散列地址
数字分析法
散列冲突的处理
- 拉链法(开散列法)
就是$vector
平均时间复杂度$O(n/M)$
- 开地址法(闭散列法)
线性探查法: 如果当前散列值已经有元素了,那么从左往右循环探查是否有空位置,有空位置九占
删除:新加一个标志域,表示该位置是否使用过,删除时不修改标志域
缺点:容易使元素在表中连成一片(线性聚集),影响搜索效率
二次探查法: $h(key) ,(h(key)+i^2) mod M,…$ $i$从$1$开始
双散列法:
$H_i = (h_1(key) + i \times h_2(key)) mod M ,i=0,1,2…$ $H_i$表示第$i$个候选地址
九.图论
定义和算法竞赛没啥区别
遍历要注意一下 按照课本代码 dfs
//简化版本
int vis[M];
void dfs(int u){
vis[u]=1;
printf("%d ",u);
for(int v=g.a[u];v;v=v->nextArc){
if(!vis[v])dfs(v);
}
}
因此默认所有节点只会遍历一次 bfs同样有vis数组,每个节点只会遍历一次
AOV网和拓补排序
$AOV$网:顶点活动网,其实就是$dag$图
它的拓补排序和竞赛一样,都是入度数组那个
注意一个$dag$图的拓补排序序列可以不止一种
时间复杂度$O(n+e)$
关键路径AOE网
$AOE$网是一个带权的$dag$图,用来估算一个工程的完成时间
有一个源点,入度为$0$,有一个出度为$0$点为汇点
完成工程所需的最短时间:从源点到汇点的最长路径的长度,这条路径被称为关键路径,关键路径上的边的称为关键活动
关键路径的求解:略
最小生成树
kruskal,简单
prim适用于稠密图: 选择一个起点,取最小权的边的另一个顶点加入集合。直到集合包含所有$n$个节点
最短路
dijkstra,floyd
十.排序
选择排序(不稳定)
在待排序区间中找到最小值的下标,将其与待排序区间的第一个交换位置
需要进行$n$ 次,每次代价是$n$
插入排序(稳定)
从只有一个元素的序列开始,插入待排序区间的元素值。 每次插入会移动已排序区间的数组元素
冒泡排序(稳定)
比较相邻元素,较大的元素往右移动
需要进行$n$次,每次代价是$n$
快速排序(不稳定)
选择分割元素$k$,将序列化为左右两个区间,左区间所有元素均小于等于$k$,右区间元素均大于等于$k$ 递归,元素数量小于等于$1$时,退出
归并排序(稳定)
#include <iostream>
using namespace std;
const int MAXN = 1e5 + 5;
int arr[MAXN], temp[MAXN];
void merge_sort(int left, int right) {
if (left >= right) return; // 递归终止条件
int mid = (left + right) / 2;
// 分别对左右两部分排序
merge_sort(left, mid);
merge_sort(mid + 1, right);
// 合并两个有序部分
int i = left, j = mid + 1, k = left;
while (i <= mid && j <= right) {
if (arr[i] <= arr[j]) temp[k++] = arr[i++];
else temp[k++] = arr[j++];
}
while (i <= mid) temp[k++] = arr[i++];
while (j <= right) temp[k++] = arr[j++];
// 将临时数组内容复制回原数组
for (int i = left; i <= right; i++) arr[i] = temp[i];
}
int main() {
int n;
cin >> n; // 输入数组长度
for (int i = 0; i < n; i++) cin >> arr[i]; // 输入数组元素
merge_sort(0, n - 1); // 调用归并排序
for (int i = 0; i < n; i++) cout << arr[i] << " "; // 输出排序结果
return 0;
}
堆排序(不稳定)
构造出堆然后每次取出堆顶即可